Comparaison modules et objets
La principale différence entre programmation modulaire et programmation objet en
Objective CAML provient du système de types. En effet la programmation par modules reste
dans le système de types à la ML, i.e. du polymorphisme paramétrique (même code exécuté
pour différents types de paramètres), alors que la programmation par objets
entraîne un polymorphisme ad hoc (où l'envoi d'un message à un objet déclenche
l'application de codes différents). Cela est particulièrement clair avec le sous-typage. Cette extension du système de types à la ML ne peut être simulée
en ML pur. Il
sera toujours impossible de construire des listes hétérogènes sans casser le
système de types.
La programmation modulaire et la programmation par objets sont
deux réponses sûres (grâce au typage) à l'organisation logique d'un programme,
permettent la réutilisabilité et la modifiabilité de composants logiciels. La programmation
par objets en Objective CAML
autorise le polymorphisme paramétrique (classes paramétrées)
et d'inclusion (envoi de messages) grâce à la liaison tardive et au sous-typage,
avec des restrictions dues à l'égalité, ce qui facilite une programmation
incrémentielle.
La programmation modulaire permet de restreindre le polymorphisme
paramétrique et utilise la liaison immédiate ce qui peut
être utile pour conserver l'efficacité de l'exécution.
Le modèle de la programmation modulaire permet de facilement étendre les
fonctionnalités sur des types de données récursifs non extensibles. Si l'on désire ajouter un cas dans
un type somme, il sera nécessaire de modifier une bonne
partie des sources.
Le modèle de la programmation objet définit un ensemble récursif de données
à partir de classes. On prend une classe par cas de données.
Efficacité d'exécution
La liaison retardée correspond à une indirection dans le tableau des méthodes (voir page
??). Comme l'accès, de l'extérieur de la classe, à une variable d'instance passe
aussi par un envoi de message, cette accumulation d'indirections
peut se révéler coûteuse.
Pour montrer cette perte d'efficacité, nous construisons la hiérarchie de classe suivante :
# class virtual test () =
object
method virtual somme : unit -> int
method virtual somme2 : unit -> int
end;;
# class a x =
object(self)
inherit test ()
val a = x
method a = a
method somme () = a
method somme2 () = self#a
end;;
# class b x y =
object(self)
inherit a x as super
val b = y
method b = b
method somme () = b + a
method somme2 () = self#b + super#somme2()
end;;
On compare ensuite les temps d'exécution entre d'une part
l'envoi des messages somme somme2 sur une instance
de la classe b et d'autre part l'appel à la fonction f suivante.
# let f a b = a + b ;;
# let iter g a n = for i = 1 to n do ignore(g a) done ; g a ;;
# let go i j = match i with
1 -> iter (fun x -> x#somme()) (new b 1 2) j
| 2 -> iter (fun x -> x#somme2()) (new b 1 2) j
| 3 -> iter (fun x -> f 1 x) 2 j ;;
# go (int_of_string (Sys.argv.(1))) (int_of_string (Sys.argv.(2))) ;;
Pour 10 millions d'itérations, on obtient les résultats suivants :
| |
code-octet |
natif |
| cas 1 |
07,5 s |
0,6 s |
| cas 2 |
15,0 s |
2,3 s |
| cas 3 |
06,0 s |
0,3 s |
Cet exemple a été construit dans le but de montrer que la liaison
retardée a un coût par rapport à la liaison statique habituelle. Ce coût
dépend de la quantité de calcul par rapport au nombre d'envois de
messages dans une méthode. L'utilisation du compilateur natif diminue
la partie calcul sans changer la partie indirection du test.
On s'aperçoit dans le cas 2 que les multiples indirections à l'envoi
du message somme2 ont un coût incompressible.
Exemple : interface graphique
La bibliothèque graphique UPI (voir page ??)
a été conçue en utilisant le noyau fonctionnel/impératif du langage.
Elle s'adapte très facilement sous forme de modules.
Chaque composant devient un module indépendant, permettant ainsi une
harmonisation
des noms des fonctions.
Pour ajouter un composant, il est nécessaire de connaître le type
concret des composants. Au nouveau module de modifier les champs nécessaires pour
décrire son affichage et ses comportements.
Elle peut aussi se réécrire en objet. Pour cela on construit la
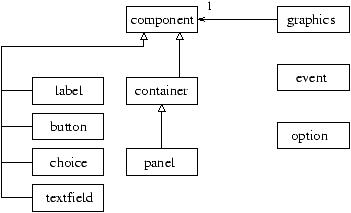
hiérarchie de classes de la figure 16.1.
Figure 16.1 : hiérarchie de classes pour Upi
Il est plus aisé d'ajouter de nouveaux composants grâce à l'héritage qu'en utilisant
les modules,
Néanmoins, l'absence de surcharge nécessite toujours un codage des options en tant
que paramètres des méthodes. L'utilisation de la relation de sous-typage
permet de facilement construire la liste des composants d'un conteneur.
La liaison retardée sélectionne les méthodes propres au composant.
L'intérêt de l'objet provient aussi de la possibilité d'étendre ou de modifier le
contexte graphique, et les autres types utilisés, toujours grâce à l'héritage.
C'est pour cela que les principales bibliothèques graphiques sont organisées selon
le modèle objet.
Traduction de modules en classes
Un module simple ne déclarant qu'un seul type et ne possédant pas de fonction polymorphe
indépendante du type déclaré peut se traduire en une classe. Selon la nature du type
utilisé (type enregistrement ou type somme) on traduit le module en classe de manière différente.
Déclarations de types
Type enregistrement
Un type enregistrement s'écrit directement sous forme d'une classe où chaque champ de l'enregistrement devient une variable
d'instance.
Type somme
Un type somme se traduit en plusieurs classes en utilisant le modèle de conception <<composite>>. Une classe abstraite décrit
les opérations (les fonctions) sur ce type. Chaque branche du type somme devient alors une sous-classe de la classe
abstraite et
implante les méthodes abstraites pour sa branche. Il n'y a plus alors de <<filtrage de motif>> mais choix
de la méthode spécifique à la branche.
Types paramétrés
Les types paramétrés s'implantent par des classes paramétrées.
Types abstraits
On peut considérer une classe comme un type abstrait. À aucun moment l'état interne de la classe n'est visible à l'extérieur de sa hiérarchie. Néanmoins rien n'empêche de définir une sous-classe pour accéder aux variables d'instances d'une classe.
Types mutuellement récursifs
Les déclarations de types mutuellement récursifs se traduisent par des déclarations de classes mutuellement récursives.
Déclarations de fonctions
Les fonctions dont un paramètre dépend du type t du module se
traduisent en méthodes. Les fonctions où n'apparaît pas le type t
peuvent être déclarées private dans la mesure où leur appartenance au
module n'est pas directement liée au type t. Cela a de plus
l'avantage de ne pas poser problème si des variables de types
apparaissent dans le type des paramètres. Se pose alors le problème des
fonctions dont un paramètre est du type t et un autre
est du type 'a. Ces fonctions sont très rares dans les modules
de la bibliothèque standard. On distingue les modules <<particuliers>>
comme Marshal ou Printf qui ont un typage non standard,
des modules sur les structures linéaires comme List. Pour ce
dernier la fonction fold_left, de type ('a -> 'b ->
'a) -> 'a -> 'b list -> 'a, est difficilement traduisible telle
quelle dans une méthode de la classe ['b] liste car la
variable de type 'a est libre et ne peut apparaître dans le
type de la méthode. Plutôt que d'ajouter un paramètre de type à la
classe liste, il est préférable de sortir ces fonctions dans
de nouvelles classes, paramétrées par 2 variables de types et
possédant un champ liste.
Méthodes binaires
Les méthodes binaires en dehors du sous-typage ne posent pas de difficulté.
Autres déclarations
Déclarations de valeurs non fonctionnelles.
On peut accepter de déclarer les valeurs non fonctionnelles en dehors
des classes. Il en est de même pour les exceptions.
Exemple : listes avec itérateur
On cherche à traduire en objet un module ayant la signature LISTE
suivante :
# module type LISTE = sig
type 'a liste = C0 | C1 of 'a * 'a liste
val add : 'a liste -> 'a -> 'a liste
val length : 'a liste -> int
val hd : 'a liste -> 'a
val tl : 'a liste -> 'a liste
val append : 'a liste -> 'a liste -> 'a liste
val fold_left : ('a -> 'b -> 'a) -> 'a -> 'b liste -> 'a
end ;;
On déclare tout d'abord la classe abstraite 'a liste
correspondant à la définition du type.
# class virtual ['a] liste () =
object (self : 'b)
method virtual add : 'a -> 'a liste
method virtual empty : unit -> bool
method virtual hd : 'a
method virtual tl : 'a liste
method virtual length : unit -> int
method virtual append : 'a liste -> 'a liste
end ;;
On définit ensuite les deux sous-classes c1_liste et c0_liste pour chaque composant du type somme. Chacune de ces classes doit définir les méthodes de la classe abstraite ancêtre.
# class ['a] c1_liste (t, q) =
object (self )
inherit ['a] liste () as super
val t = t
val q = q
method add x = new c1_liste (x, (self : 'a #liste :> 'a liste))
method empty () = false
method length () = 1 + q#length()
method hd = t
method tl = q
method append l = new c1_liste (t,q#append l)
end ;;
# class ['a] c0_liste () =
object (self)
inherit ['a] liste () as super
method add x = new c1_liste (x, (self : 'a #liste :> 'a liste))
method empty () = true
method length () = 0
method hd = failwith "c0_liste : hd"
method tl = failwith "c0_liste : tl"
method append l = l
end ;;
# let l = new c1_liste (4, new c1_liste (7, new c0_liste ())) ;;
val l : int liste = <obj>
La fonction LISTE.fold_left n'a pas été incorporée dans la
classe liste pour éviter d'introduire un nouveau paramètre de
type. On préfère définir la classe fold_left pour
implanter ce traitement. Pour cela, on utilise une variable d'instance
fonctionnelle (f).
# class virtual ['a,'b] fold_left () =
object(self)
method virtual f : 'a -> 'b -> 'a
method iter r (l : 'b liste) =
if l#empty() then r else self#iter (self#f r (l#hd)) (l#tl)
end ;;
# class ['a,'b] gen_fl f =
object
inherit ['a,'b] fold_left ()
method f = f
end ;;
On construit alors une instance de la classe gen_fl pour
l'addition :
# let afl = new gen_fl (+) ;;
val afl : (int, int) gen_fl = <obj>
# afl#iter 0 l ;;
- : int = 11
Simulation d'héritage avec des modules
La relation d'héritage entre classes permet de récupérer dans une sous-classe
l'ensemble des déclarations de variables et de méthodes de la classe ancêtre.
On peut simuler cette relation en utilisant des modules.
La sous-classe qui hérite se transforme en un module paramétré
dont le paramètre est la classe ancêtre. L'héritage multiple augmente le
nombre de paramètres du module.
On reprend l'exemple classique sur les points et les points colorés
décrit au chapitre 15 pour le traduire en modules.
La classe point devient le module Point de signature POINT
suivante.
# module type POINT =
sig
type point
val new_point : (int * int) -> point
val get_x : point -> int
val get_y : point -> int
val moveto : point -> (int * int) -> unit
val rmoveto : point -> (int * int) -> unit
val display : point -> unit
val distance : point -> float
end ;;
La classe point_colore se transforme en un module paramétré PointColore
dont le
paramètre est de signature POINT.
# module PointColore = functor (P : POINT) ->
struct
type point_colore = {p:P.point;c:string}
let new_point_colore p c = {p=P.new_point p;c=c}
let get_c self = self.c
(* début *)
let get_x self = let super = self.p in P.get_x super
let get_y self = let super = self.p in P.get_y super
let moveto self = let super = self.p in P.moveto super
let rmoveto self = let super = self.p in P.rmoveto super
let display self = let super = self.p in P.display super
let distance self = let super = self.p in P.distance super
(* fin *)
let display self =
let super = self.p in P.display super; print_string ("de couleur "^ self.c)
end ;;
La lourdeur des déclarations <<héritées>> peut être allégée par une procédure automatique de
traduction ou une extension du langage.
Les déclarations récursives de méthodes pourraient
s'écrire par un seul let rec ... and. L'héritage multiple entraîne des
foncteurs à plusieurs paramètres. Le coût de la redéfinition n'est pas plus
grand que la liaison tardive.
La liaison tardive n'est pas implantée dans cette simulation. Pour le
faire, il faut définir un enregistrement où chaque champ
correspond au type des fonctions/méthodes.
Limitations de chaque modèle
Le modèle fonctionnel/modulaire offre un cadre rassurant mais rigide pour
la modifiabilité du code. Le modèle objet d'Objective CAML souffre de la
double vision des classes : structuration et type, impliquant
l'absence de surcharge et l'impossibilité d'effectuer des contraintes de
type d'un type ancêtre vers un type descendant.
Modules
Les principales limitations du modèle fonctionnel/modulaire
proviennent de la difficulté d'extensibilité des types. Bien que les
types abstraits permettent de s'affranchir de la représentation
concrète d'un type, leur utilisation dans les modules paramétrés
nécessite d'indiquer à la main les égalités de types entre modules,
compliquant l'écriture des signatures.
Dépendances récursives
Le graphe de dépendances des modules d'une application ne contient pas
de cycle (DAG). Cela implique d'une part de ne pas avoir de types
mutuellement récursifs entre deux modules et d'autre part d'empêcher
les déclarations de valeurs mutuellement récursives.
Difficultés d'écriture des signatures
Un des intérêts de l'inférence de types est de ne pas nécessiter
l'écriture des types des paramètres des fonctions. La description des
signatures fait perdre cette pratique. Il devient nécessaire de
spécifier les types des déclarations de la signature <<à la main>>. On
peut utiliser l'option -i du
compilateur ocamlc pour afficher le type de toutes les
déclarations globales d'un fichier .ml et utiliser cette
information pour construire la signature d'un module. Dans ce cas, on
perd la démarche <<génie logiciel>> qui consiste à spécifier le module
avant de l'implanter. De plus si la signature et le module subissent
des changements importants, on doit revenir à l'édition de la
signature. Les modules paramétrés ont besoin des signatures de leurs
paramètres et celles-ci doivent aussi être décrites manuellement. Enfin
si on associe une signature fonctionnelle à un module paramétré, il
n'existe pas de possibilité pour récupérer la signature résultat de
l'application du foncteur. Cela oblige à écrire principalement des
signatures non fonctionnelles, quitte à les assembler par la suite
pour construire une signature fonctionnelle.
Exportation et importation de modules
L'importation des déclarations d'un module simple
s'effectue soit par la notation pointée (Module.nom), soit directement par
le nom d'une déclaration (nom) si le module a été ouvert (open Module).
Les déclarations de l'interface du module
importé ne sont pas directement exportables au niveau du module en
cours de définition.
Celui-ci a accès à ces déclarations, mais elles ne sont pas considérées
comme des déclarations du module. Pour ce faire il est nécessaire de déclarer,
à la manière de la simulation d'héritage, les valeurs importées.
Il en est de même pour les modules paramétrés. Les déclarations du module
paramètre ne sont pas considérées comme des déclarations du module courant.
Objets
Les principales limitations du modèle objet d'Objective CAML proviennent du typage.
-
pas de méthode contenant un paramètre de type libre;
- difficulté d'échappement du type de la classe dans une de ses méthodes;
- absence de contrainte de type d'ancêtre vers descendant;
- pas de surcharge.
Le point le plus déroutant quand on aborde l'extension objet d'Objective CAML provient de l'impossibilité
de construire des méthodes contenant un type paramétré dont le paramètre de type
est libre.
La déclaration d'une classe peut être vue comme la définition d'un nouveau type et suit en cela la règle générale qui interdit la présence de variables de type libres dans une déclaration de type.
C'est pour cela que les classes paramétrées sont indispensables dans le
modèle objet d'Objective CAML car elles permettent de lier ces variables de type.
Absence de surcharge
Le modèle objet d'Objective CAML ne permet pas la
surcharge de méthode. Comme le type d'un objet correspond aux types de ces méthodes,
le fait de posséder plusieurs méthodes de même nom mais de types différents
entraîne de nombreuses ambiguïtés, dues au polymorphisme paramétrique,
que le système ne pourrait
résoudre que dynamiquement, ce qui est contradictoire avec la vision totalement statique du typage. Prenons une classe exemple qui possède deux méthodes message possédant pour la première un paramètre entier et pour la deuxième un paramètre
flottant. Soit e une instance de cette classe et
soit la fonction f suivante :
# let f x a = x#message a ;;
Les appels f e 1 et f e 1.1 ne peuvent pas statiquement
être résolus car il n'y a pas dans le code de la fonction f d'informations
spécifiques à la classe exemple.
Une conséquence immédiate de cette absence est l'unicité des constructeurs d'instances.
La déclaration d'une classe indique les paramètres à fournir
à la fonction de création. Celle-ci est unique.
Initialisation
L'initialisation des variables d'instance déclarées
dans une classe peut être problématique quand elle doit se calculer à partir des valeurs passées à la construction.
Égalité entre instances
La seule égalité qui fonctionne sur les objets est l'égalité
physique. L'égalité structurelle retourne toujours false quand elle s'applique à deux
objets physiquement différents. Cela peut surprendre dans la mesure où deux instances d'une même
classe partagent la même table des méthodes. On pourrait imaginer un test physique sur la table des méthodes et un test structurel sur les valeurs (val) des objets. Ce sont des choix d'implantation
à la manière du filtrage linéaire.
Hiérarchie de classes
On ne trouve aucune hiérarchie de classes dans la distribution du langage.
En effet l'ensemble des bibliothèques sont fournies sous forme de modules simples ou
paramétrés. Cela montre que l'extension objet du langage est encore en cours de stabilisation et milite peu en faveur de son emploi intensif.